[论文阅读] UniAdapter: Unified Parameter-Efficient Transfer Learning for Cross-modal Modeling
Motivation
先前的工作都是考虑的单一模态或者单一下游任务,且没有考虑过跨模态之间的交互和知识共享。
优势:
知识共享
为保证语言查询在交叉注意力中的完整性,对语言查询进行了残差学习
无参数的帧感知注意力,能够无成本地统一视频和图像模态,不仅适用于更多的下游任务,且能够缓解视频帧中的噪声问题
Methodology
Preliminary
Vision-language Framework
用单模态编码器提取视觉特征
对于视频-语言任务,首先用视觉编码器提取每一帧的特征
Adapter
每个 adapter 包含一个下投射层
Residual Leaning for Language Queries
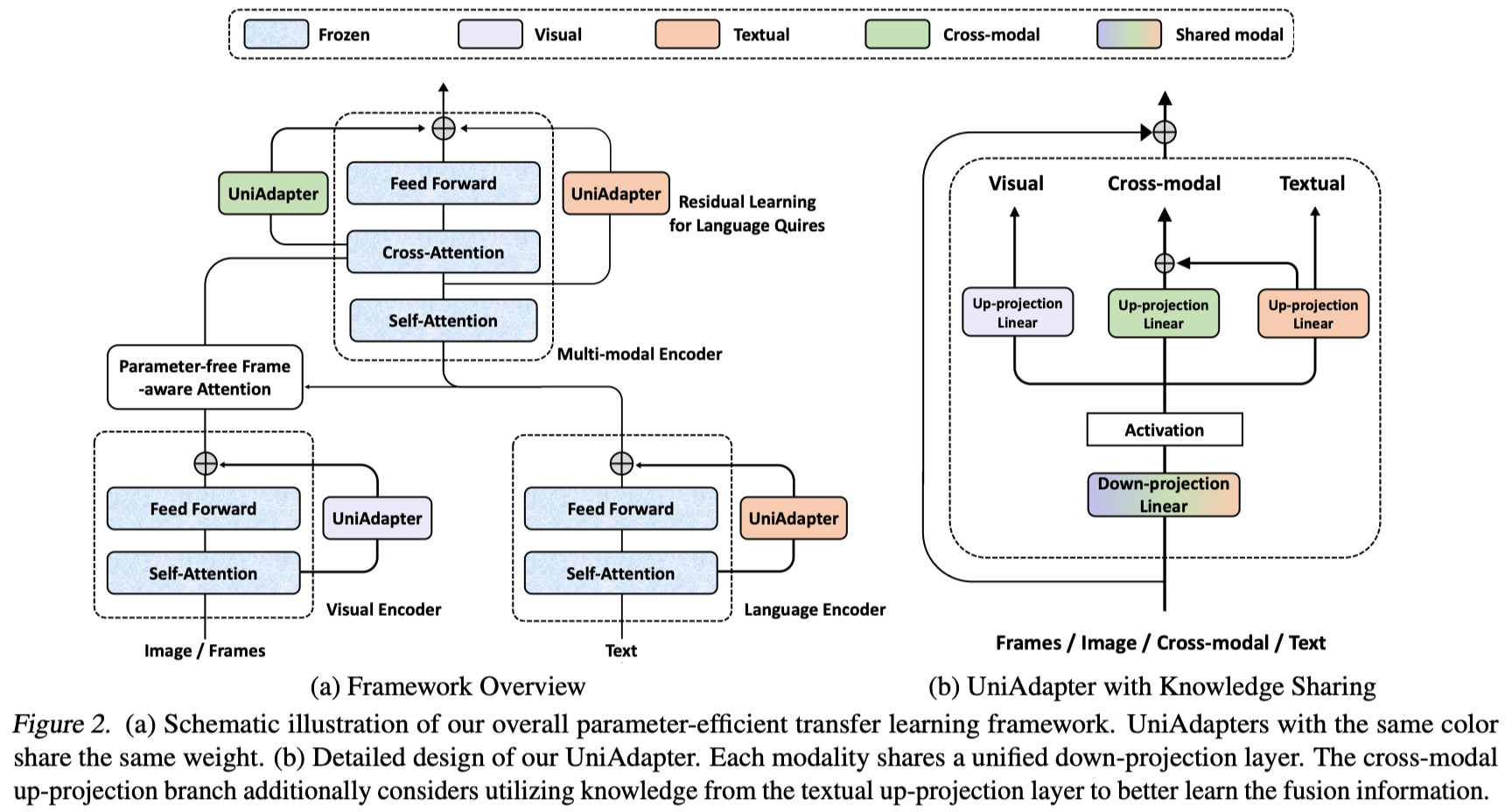
常规的方法是在编码器的多头注意力模块后直接插入 adapter ,但是这种做法很难处理混合信息,而且有可能在交叉注意力处理过程中破坏语言查询的完整性,因而提出用于语言查询的残差学习。
每个多模态编码器包含一个多头自注意力,一个多头交叉注意力和一个 FFN 。多模态编码器将文本特征作为输入,将视觉信息注入到每个交叉注意力层中。每个交叉注意力层将自注意力的输出特征

UniAdapter
将视觉-语言模型迁移到下游任务中,一个最直接的方法就是为每一个模态模块使用 adapter,但是这样会带来较高的参数。而且,这些 adapter 之间没有跨模态交互,进而导致性能不好。UniAdapter通过共享部分权重的方式将单模态、多模态的 adapter 统一到一个框架下。
UniAdapter 的核心思想就是共享多种模态的知识来增强跨模态交互,同时减少参数量。UniAdapter 包括一个统一的下投射层
Unimodal Case
尽管使用了统一的下投射层来进行跨模态知识共享,但学习特定模态的表征对于单模态编码器也很重要。所以,使用了特定模态的上投射层
视觉和文本编码器使用相同的 transformer encoder 结构,遵循 MAM 的设置将 UniAdapter 放在 自注意力层和前馈层之间。
Cross-modal Case
此外还利用一个特定的上投射层进行多模态编码器的迁移学习。但是输入特征包含了查询特征和跨模态融合特征。用单个 adapter 来学习这写混合信息非常困难。因此考虑上文提到的,在 UniAdapter 中重复利用文本上投射层
Parameter-free Frame-aware Attention
对于给定的视频文本对,所提取的帧特征为