[论文阅读] LANGUAGE MODELLING WITH PIXELS
Approach
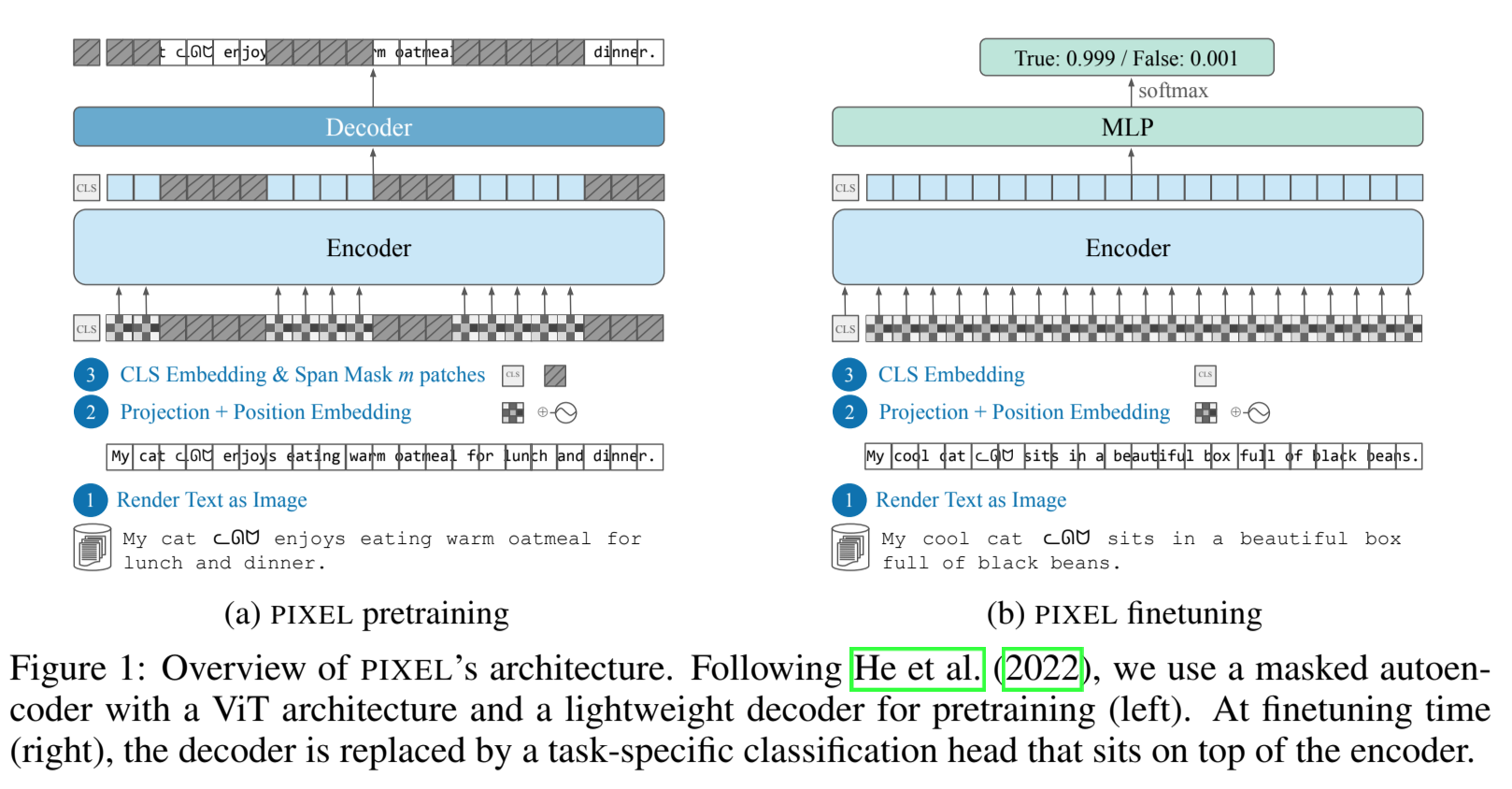
三个主要组件: * 文本渲染器:把文字处理成图片 * 编码器:对图片的未遮盖区域进行编码 * 解码器:重建遮盖区域像素
TEXT RENDERER

把文本渲染成 RGB 图片,
ARCHITECTURE
Patch Span Masking

不同于 ViT-MAE 的随机屏蔽或者 BEiT 中块级别的屏蔽,PIXEL 采用
FINETUNING
Extractive Question Answering(QA)
使用滑动窗口的方法来提取超过最大序列长度的例子的答案
使用一个线性分类器来预测包含答案的间断的开始和结束的 patch
[论文阅读] LANGUAGE MODELLING WITH PIXELS
http://k0145vin.xyz/2023/04/26/论文阅读-LANGUAGE-MODELLING-WITH-PIXELS/