[论文阅读] AIM: ADAPTING IMAGE MODELS FOR EFFICIENT VIDEO ACTION RECOGNITION
AIM: ADAPTING IMAGE MODELS FOR EFFICIENT VIDEO ACTION RECOGNITION
Introduction
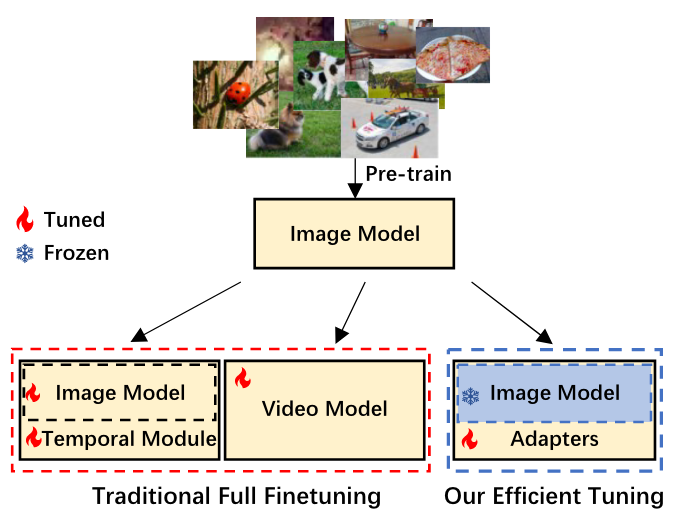
在视频理解领域,目前主流的两种做法: 1. 在Image Model上加Temporal Module 2. 将Image Model扩展成Video Model
这些做法存在明显的缺点: 1. 需要full fine-tuning,耗费计算资源 2. 预训练的图像模型具有出色的可移植性,是否还有必要进行full fine-tuning?不充分的fine-tuning可能会破坏模型良好的泛化能力,“灾难性遗忘”
image-to-image,video-to-video的PEFT工作很多,但是image-to-video的PEFT工作还比较少,因为image model缺少时序推理能力。
在这篇文章中,作者提出了AIM用于视频动作识别。将预训练的图像模型参数冻结,添加一些轻量化的adapter进行fine-tuning,可以以更少的参数量达到SOTA甚至更好的效果。

先添加了spatial adaptation,但是预训练的图像模型在视频理解中已经有足够好的空间建模能力了;复用了预训练图像模型的self-attention层,作用于时间维度,添加temporal adaptation;最后添加joint adaptation。
Methodology
Prelimnary
一般的每个transformer block由一个多头自注意力、一个MLP层、LN层和残差连接构成。写为:
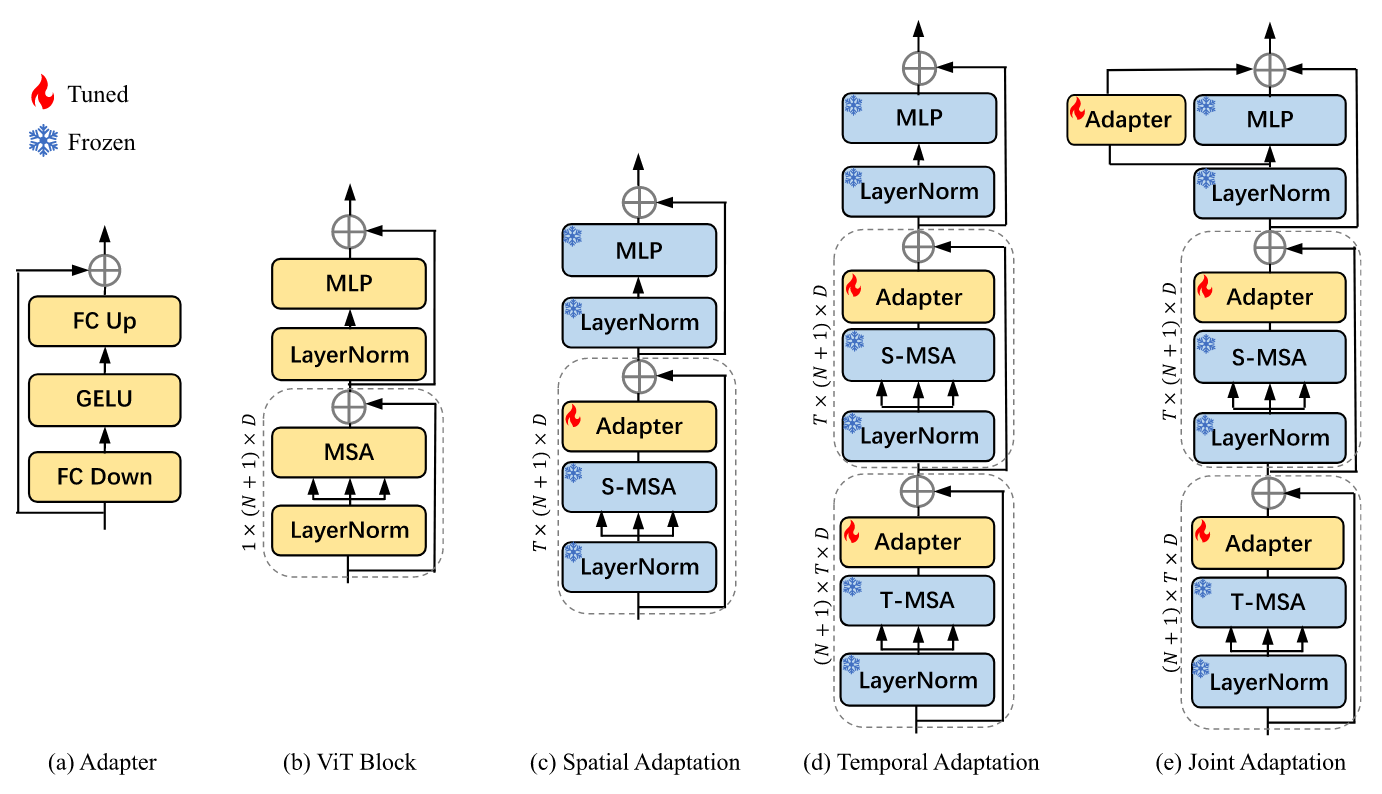
Spatial Adapation
预训练模型已经在大规模数据集上进行了训练,对下游任务有着强大的迁移能力,作者相信它们在视频动作识别中只经过很小的改动就能有很好的空间建模能力。
Adapter包含了两个全连接层、一个激活函数和一个残差连接,第一个全连接层降维,第二个全连接层升维。为了将预训练的空间特征应用到视频数据中,作者在自注意力层之后加入了一个Adapter,称为spatial adaptation。在训练过程中,transformer层的参数都是冻结的,只有adpater的参数是更新的。

上表表明:adapter确实帮助了冻结的图像模型学习到了很好的空间信息,但是与full fine-tuned的模型的性能还有很大的差别,这是因为只有spatial adaptation缺少学习视频中时序信息的能力。
Temporal Adaptation
先前的方法中为了获取时序信息都会给预训练的图像模型添加temporal modules。然而,添加新的temporal modules,无论是temporal attention还是temporal encoder/decoder,都会引入大量额外的可调节参数。而且,这些新的模块都需要full fine-tuning。
为解决这一问题,作者提出了一种新的策略:复用图像模型中预训练好的自注意力层来做时序建模。将原来的自注意力层称为S-MSA,用于空间建模;复用的自注意力层称为T-MSA,用于时序建模,把T-MSA放在S-MSA前面。给定video pathch embedding
Joint Adaptation
最后,引入了与MLP层平行的Adapter,称为joint adaptation。这个adapter跟temporal adaptation中的拥有相同的结构。
最终的计算过程可以写为:
Conclusion
T-MSA只是简单复用了S-MSA,对于视频的时序建模能力不够强大。视频时序建模可以看成是一种序列建模的形式,因此以后可以考虑使用文本或者音频模型的预训练权重,而不是图像模型的。