[论文阅读]DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
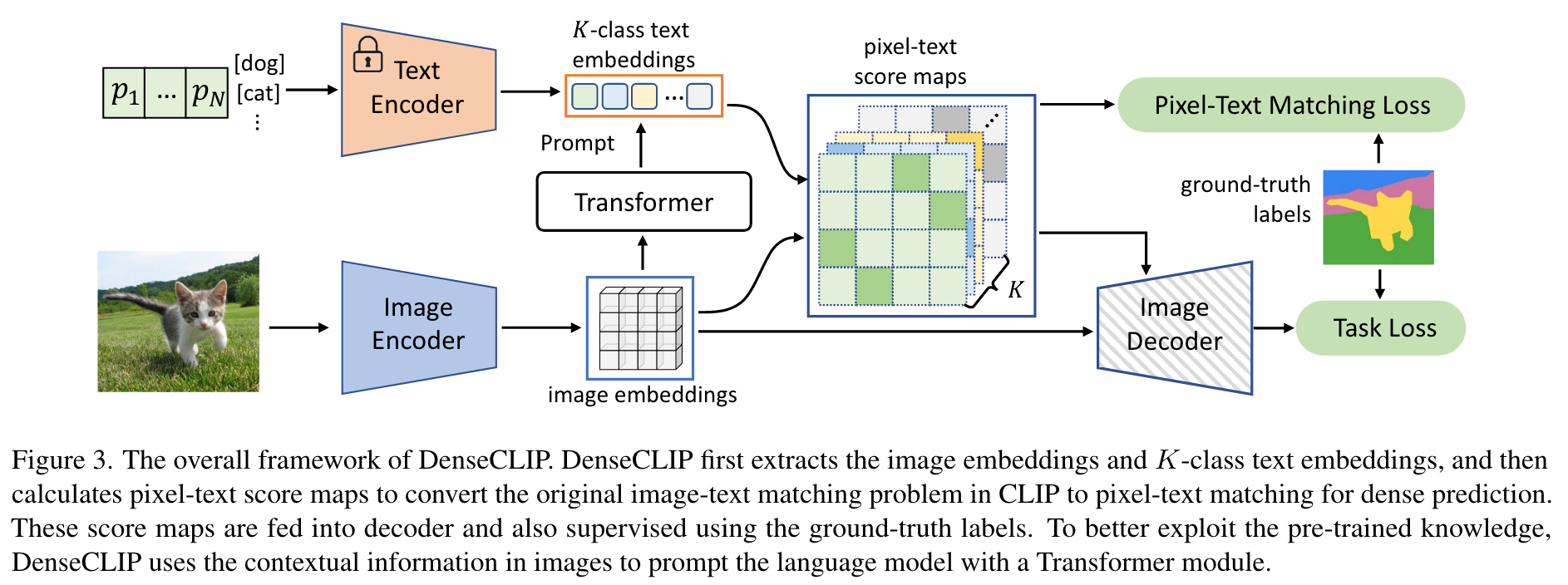
Approach
Context-Aware Prompting
Language-domain prompting
不再使用人工设计的模板作为文本提示,受CoOp的启发,使用可学习的文本上下文作为基线,只包含语言域的提示,则文本编码器的输入变为:
其中,
Vision-to-language prompting
包含视觉内容的描述可以是文本更加精确。因此,使用transformer decoder中的交叉注意力机制来建模视觉和语言之间的交互。 
有两种不同的上下文感知提示策略,正如Fig4中展示的。第一种策略称为pre-model prompting,把特征
另外一种选择是在文本编码器之后细化文本特征,称为post-model prompting。使用CoOp生成文本特征,并直接作为transformer decoder的查询:
尽管两种版本的目标相同,但是文章作者更倾向于后提示,主要原因有两个:(1)后提示更高效。由于预提示的输入依赖于图像,因此在推理过程中需要文本编码器额外的前向通道。在后提示的情况下,可以在训练后保存提取的文本特征,从而减少推理过程中文本编码器带来的开销。(2)实验结果也表明,后提示的性能更好。
Instantiations
Semantic segmentation
整个架构是模型无关的,可以应用于任何稠密预测任务。提出使用一个辅助目标来更好地利用像素-文本得分图进行分割。由于得分图
在这种情况下,没有真实值分割标签。为了构建类似于分割中的辅助损失,使用边界框和标签构建一个二进制目标