[论文阅读]Video Swin Transformer
Overall Architecture
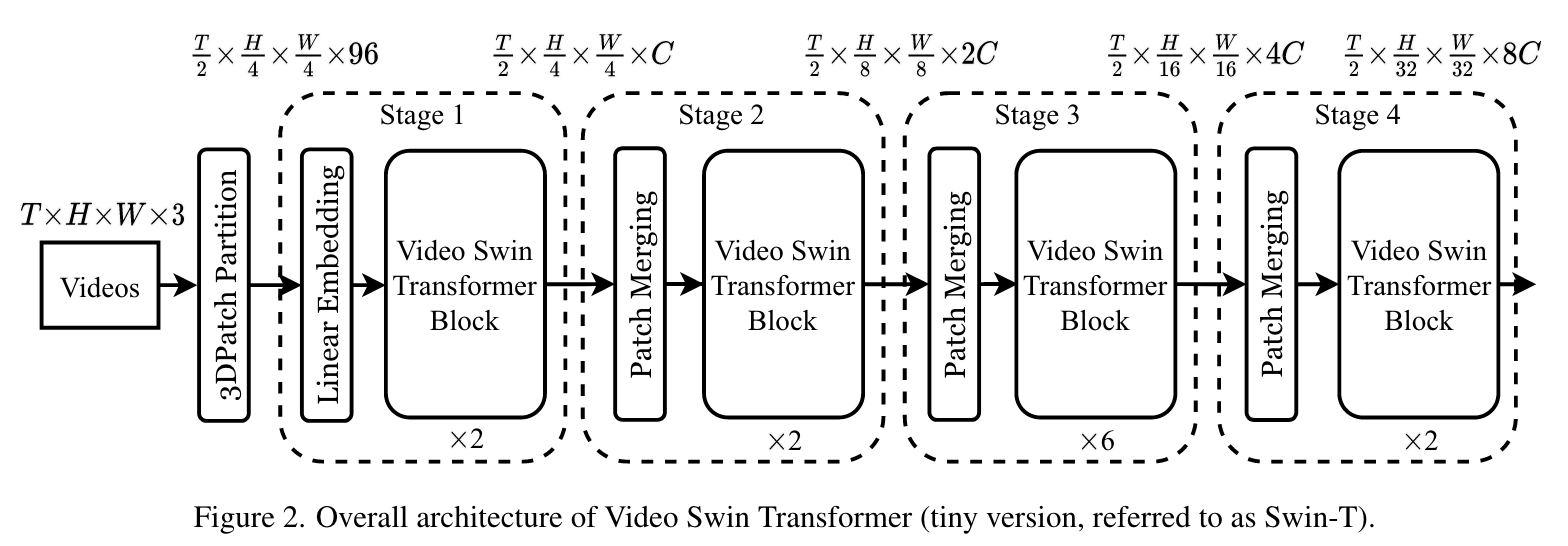 Fig2展示了Video Swin Transformer的tiny版本。输入视频的大小为
Fig2展示了Video Swin Transformer的tiny版本。输入视频的大小为
3D Shifted Window based MSA Module
Multi-head self- attention on non-overlapping 3D windows
给定一个包含
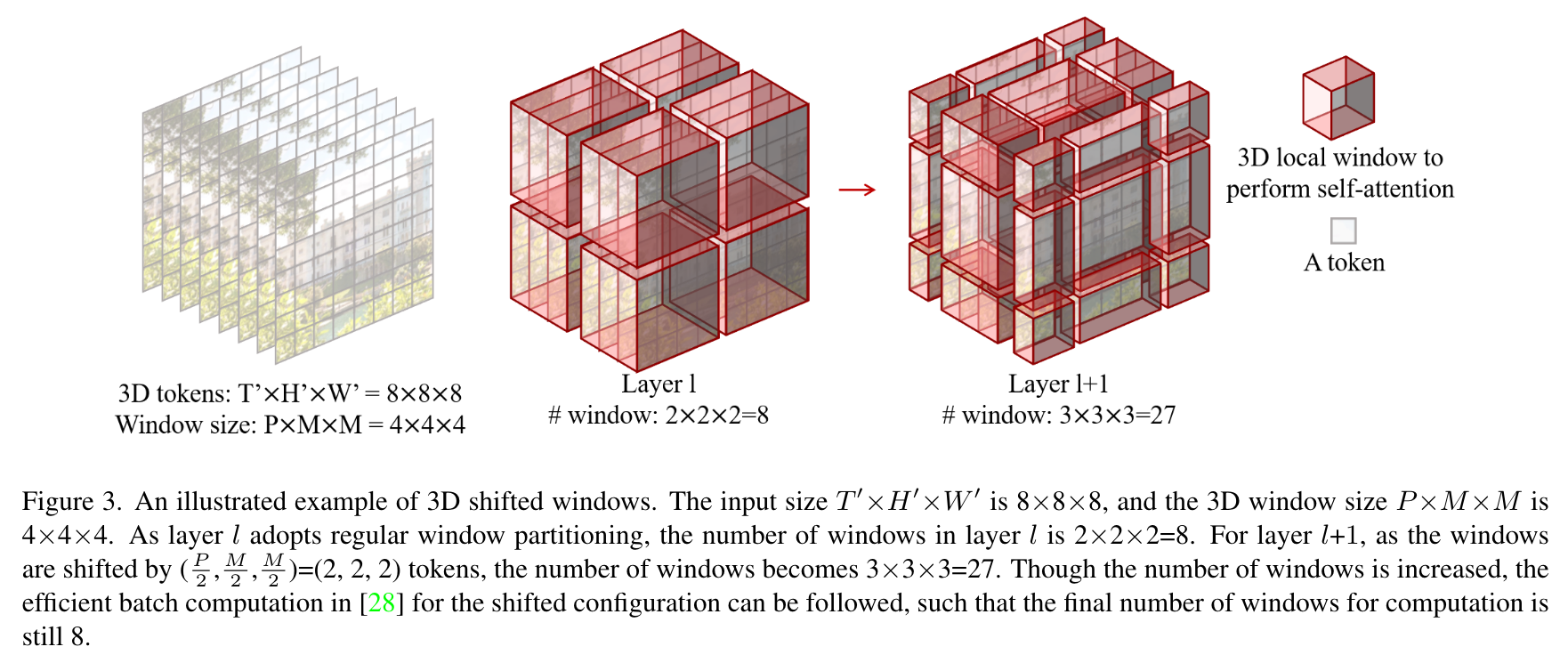
3D Shifted Windows
由于多头注意力机制应用在每个不重叠的3D窗口内,不同窗口之间缺乏联系,这可能会限制架构的表示能力。因此,将Swin Transformer中滑动的2D窗口扩展到3D,引入跨窗口联系,同时保持给予自注意力的非重叠窗口的计算效率。
给定输入的3D token的数量为
Fig3解释了这一过程。虽然窗口的数量增加了,但是根据Swin Transformer的设置,最终的计算窗口数量仍然是8.
采用滑动窗口的分割方法,计算两个连续的Video Swin Transformer块:
3D Relative Position Bias
在自注意力头引入3D相对位置偏差
[论文阅读]Video Swin Transformer
http://k0145vin.xyz/2023/03/08/论文阅读-Video-Swin-Transformer/