[论文阅读]AdaMixer: A Fast-Converging Query-Based Object Detector
TransformerEncoder、MultiScale Deformable TransformerEncoder、FPN增加了计算成本,训练需要大量的时间和数据。
提高跨图像解码查询的适应性
Object Query Decoder Revisited

Our Object Query Definition
根据object query的定义,还是将一个query解耦为两个向量:content vector \(\mathrm{q}\)和positional vetor \((x,y,z,r)\)。content vector \(\mathbf{q}\)是\(\mathbb{R}^{d_q}\)中的一个向量,\(d_q\)是通道维数。向量\((x,y,z,r)\)中\(x,y\)是bounding box的中心坐标,\(z\)是框大小的对数,\(r\)是长宽比的对数。\(x,y,z\)还可以直接表示3D特征空间中query的坐标。
Decoding the bounding box from a query
可以从位置编码中解码边界框信息。中心点\((x_B,y_B)\),宽和高\(w_B,h_B\)解码: \[ x_B=s_{base}\cdot x,y_B=s_{base}\cdot y \]
\[ w_B=s_{base}\cdot 2^{z-r},h_B=s_{base}\cdot 2^{z+r} \]
\(s_{base}\)是下采样步长偏移量,根据实验一般设置为\(s_{base}=4\)。
Adaptive Location Sampling
decoder应该自适应地针对query决定采样哪个特征。也就是说,decoder应该同时考虑位置向量\((x,y,z,r)\)和内容向量\(\mathbf{q}\)对采样位置进行采样位置进行解码。此外,decoder不仅要在\((x,y)\)空间上是自适应的,在潜在目标的尺度上也要是自适应的。具体来说,通过将多尺度特征看作一个三维特征空间,自适应地从中采样。
Multi- scale features as the 3D feature space
给定一个索引为\(j\),下采样步长为\(s_j^{feat}\)的特征图,先通过线性映射到相同的通道数\(d_{feat}\),然后计算z轴坐标: \[ z_j^{feat}=\log_2(s_j^{feat}/s_{base}) \] 然后将不同步长的特征图的高和宽重新缩放到相同的\(H/s_{base},W/s_{base}\),其中\(H,W\)是输入图像的高和宽,并将它们放在3D空间中的x轴和y轴上对齐。
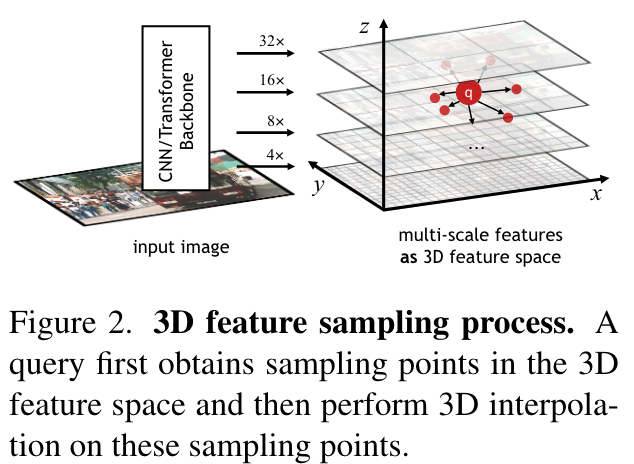
Adaptive 3D feature sampling process
一个query首先通过一个线性层生成针对点的偏移向量集合\(P_{in},\{(\Delta x_i,\Delta y_i, \Delta z_i)\}_{P_{in}}\): \[ \{(\Delta x_i,\Delta y_i, \Delta z_i)\}_{P_{in}}={\rm Linear}(\mathbf{q}) \] 然后,根据query \(i\)的的位置向量将这些偏移量转化为采样位置: \[ \left\{\begin{matrix} \tilde{x}_i=x+\Delta x_i\cdot 2^{z-r},\\ \tilde{y}_i=y+\Delta y_i\cdot 2^{z+r}, \\ \tilde{z}_i=z+\Delta z_i, \end{matrix}\right. \] 值得注意的是,从query中解码用来描述bounding box的区域\(\{\Delta x_i,\Delta y_i\in[-0.5,0.5]\}\)。偏移量并不限于此范围内,这就意味着query可以在bounding box外进行采样。得到集合后,采样器即可在3D空间内对给定的点进行采样。在现有的实现中,3D空间内的插值是组合实现的:首先在\((x,y)\)平面内通过双线性插值对给定点进行采样,然后在给定采样\(\tilde{z}\)的情况下通过高斯加权对z轴进行采样,其中特征图\(j\)的权重为: \[ \tilde{w}_j=\frac{\exp(-(\tilde{z}-z_j^{feat})^2/\tau_z)}{\sum_j\exp(-(\tilde{z}-z_j^{feat})^2\tau_z)} \] 其中\(\tau_z\)是z轴上插值的软化系数,在本文中取\(\tau_z=2\)。特征图的通道数为\(d_{feat}\),采样特征矩阵\(\mathbf{x}\)的形状为\(\mathbb{R}^{p_{in}\times d_{feat}}\)。通过利用显式、自适应的一致的位置信息和与query对应的尺度进行采样,自适应3D特征采样处理简化了decoder 的学习过程。
Group sampling
为了尽可能采样多点的特征,引入了群体采样机制,类似于注意力机制中的多头注意力和群体卷积。群体采样首先将3D特征空间的通道数\(d_{feat}\)分成\(g\)组,每组为\(d_{feat}/g\),每组分别进行3D采样。采用分组采样机制,对于每个query,decoder可以生成\(g\cdot P_{in}\)组偏移向量,来丰富采样点的多样性,利用这些点更丰富的空间结构特征。采样特征矩阵\(\mathbf{x}\)的形状就变成了\(\mathbb{R}^{g\times P_{in}\times (d_{feat}/g)}\)。
Adaptive Content Decoding
为了捕获\(\mathbf{x}\)空间和通道维数的相关性,提出了分别对每个维数中的内容的有效解码。设计了一个MLP-mixer的简化、自适应变体,进行自适应混合,动态混合权重类似于卷积中的dynamic filters。

如上图所示,在query的参与下,依次进行自适应通道混合和自适应空间混合,以利用自适应通道语义信息和空间结构。
Adaptive channel mixing
给定一个query的采样特征矩阵\(\mathbf{x}\in\mathbb{R}^{P_{in}\times C}\),其中\(C=d_{feat/g}\),自适应通道混合(ACM)会使用基于\(\mathbf{q}\)的动态权重在通道维数对\(\mathbf{x}\)进行转换以自适应地增强通道语义: \[ M_c={\rm Linear}(\mathbf{q})\in\mathbb{R}^{C\times C} \]
\[ {\rm ACM}(\mathbf{x})={\rm ReLU(LayerNorm}(\mathbf{x}M_c)), \]
其中\({\rm ACM}(\mathbf{x})\in\mathbb{R}^{P_{in}\times C}\)是通道混合特征的输出,线性层对于每一组都是独立的。然后对混合输出的所有维度都进行层正则化。在这一步中,动态权重在3D空间中的不同采样点之间是共享的,类似于Sparse R-CNN中RoI特征的\(1\times1\)的自适应卷积。
Adaptive spatial mixing
为了使query对采样特征的空间结构自适应,引入了自适应空间混合(ASM)。如上图所示,先对通道混合特征矩阵进行转置,然后对其空间维度应用动态核: \[ M_s={\rm Linear}(\mathbf{q})\in\mathbb{R}^{P_{int}\times P_{out}} \]
\[ {\rm ASM}(\mathbf{x})={\rm ReLU(LayerNorm)}(\mathbf{x}^T M_s), \]
其中\({\rm ASM}(\mathbf{x})\in\mathbb{R}^{C\times P_{out}}\)是空间混合输出,\(P_{out}\)是空间混合输出数量。动态权重在不同通道间是共享的。由于采样点可能来自不同的特征尺度,ASM自然需要涉及多尺度交互建模,这对于实现高性能目标检测是非常必要的。
Overall AdaMixer Detector
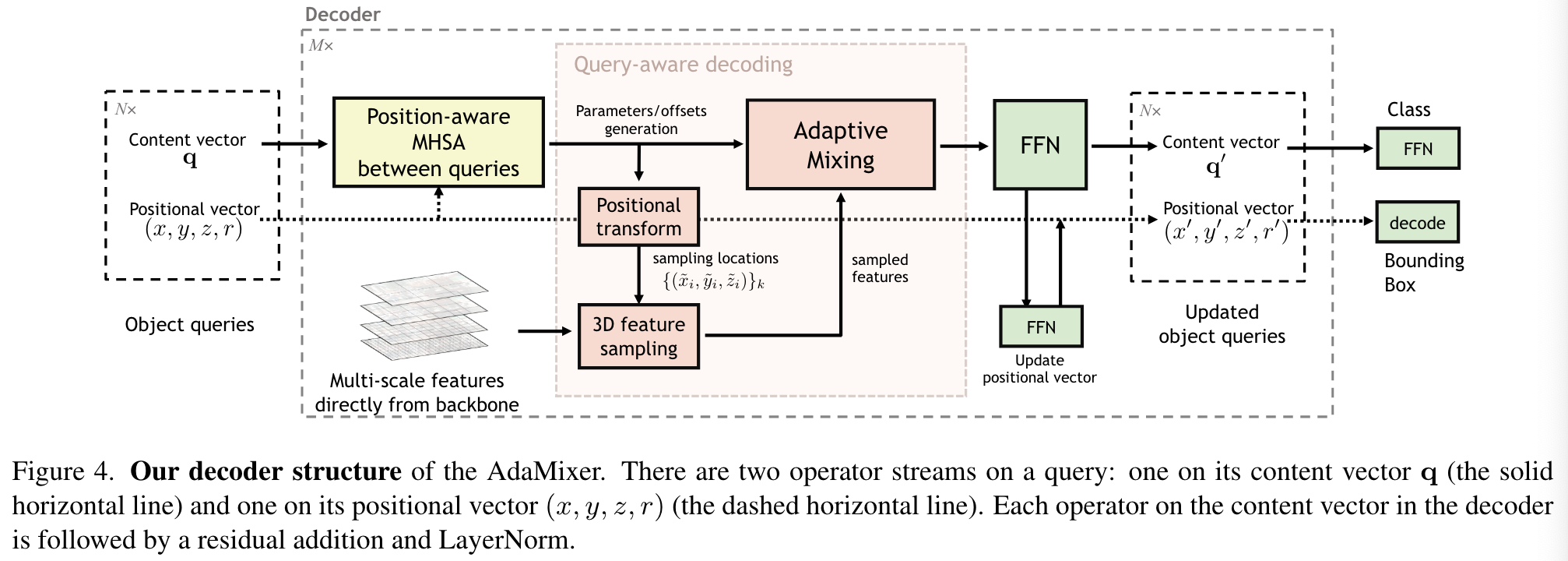
query的位置向量在阶段结束后由另一个FFN来做更新: \[ x^\prime = x+\Delta x\cdot 2^z,y^\prime=t+\Delta y\cdot2^z, \]
\[ z^\prime=z+\Delta z,r^\prime=r+\Delta r, \]
其中\((\Delta x,\Delta y, \Delta z,\Delta r)\)是由小的FFN块产生的。
Position-aware multi-head self-attentions
由于对query进行了解耦,分离出了内容和位置向量,内容向量间原始的多头自注意力机制不知道一个query与另外一个query之间的几何关系,这被证明有利于抑制冗余检测。为了实现这一点,我们将位置信息嵌入到自注意力中。正弦形式的内容向量的位置信息和\((x,y,z,r)\)组件嵌入占用了四分之一的通道。我们还将前景交集(IoF)作为query间注意力权重的偏置嵌入到query中,以显式地包含query间被包含的关系。对于每个注意力头: \[ {\rm Attn}(Q,K,V)={\rm Softmax}(QK^T/\sqrt{d_q}+\alpha B)V, \] 其中\(B_{ij}=\log(|box_i\cap box_j|/|box_i|+\epsilon)\),\(\epsilon=10^{-7}\),\(Q,K,V\in\mathbb{R}^{N\times d_q}\)代表query、key和value矩阵,\(\alpha\)是每个头的可学习参数。\(B_{ij}=0\)代表box \(i\)完全包含在box \(j\)中,\(B_{ij}=\log\epsilon\ll0\)代表box \(i\)和\(j\)之间没有重叠。