[论文阅读]Accelerating DETR Convergence via Semantic-Aligned Matching
收敛缓慢的原因:初始状态下,每个object query要跟所有的空间位置进行匹配,需要相当长的训练周期来学习与目标相关的区域。SMCA-DETR、Conditional DETR、Deformable DETR中都有提及。

造成object query无法正确聚焦于特定区域的原因是Cross-Attention之间的多个模块(Self-Attention和FFN)对object query进行了多次映射,使得object query与图像特征F的语义未对齐,也就是说,object query和图像特征F被映射到了不同的嵌入空间(Embedding Space)内。
Deformable DETR用可形变注意力机制代替原来的全局密集注意力,只关注小部分的特征
Conditional DETR、SMCA-DETR将交叉注意力模块改为空间条件化的。
Motivation: Siamese-based architecture 孪生结构
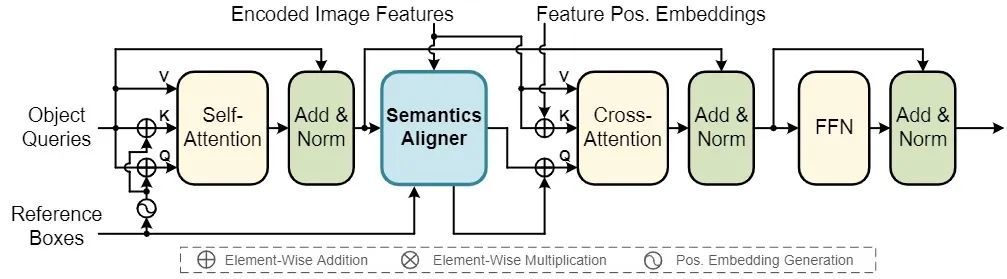
通过两个相同的子网络将匹配双方的语义对齐,以投影到相同的embedding space,便于后续匹配。为object query提供了一个强大的先验,使其只关注于语义相似的区域上。
物体的关键点和端点在目标识别和定位中非常重要,显式地搜索多个显著点,并用于语义对齐匹配
交叉注意力模块->匹配与蒸馏
对于检测任务来说,物体的显著点是识别和定位的关键。因此选择显著点的特征作为Semantics Aligner的输出。
假设注意力头的数量为
Semantics Aligner高效地产生了与编码图像特征语义对齐的object queries,但是同时也产生了问题:之前的query embedding
又利用先前的query embedding作为输入通过线性投影和sigmoid函数产生了重加权系数。通过与重加权系数相乘,新产生的query embedding和对应的position embedding都被重加权来突出重要特征,有效地利用先前的有价值的信息